What Links Here?
Outbound Links
Tagging: The Power and the Problems
"Tagging" of content is a powerful and perilous feature.
There's a few different problems and challenges —
- Synonyms aka Aliases
- Homonyms
- Stemming
- Pollution (general)
- Overuse (the law of the instrument) (a kind of good problem to have… see discussion below to wielding this)
- Performance of querying
- Tension of Amateur versus expert
- Feature of Last Resort
Then there’s “related tags” and “tag hierarchies” — a lot more problems arise here.
(Review this tweet and the associated thread.
https://twitter.com/secretgeek/status/1582557943316504576?s=46&t=7E1kl-CYQFs8u1lqskxzVw
And the related discussion at HN —
https://news.ycombinator.com/item?id=33248391
Some really wise comments there — the ones I voted up —
This seems like one of those Eternal Problems that people, whether librarians, programmers, or hobbyists, stumble across, think they'll make headway in, then discover that they've really managed to progress just a few feet across a vast and hostile surface of landmines, pitfalls, and lures. Each "obvious" step (I'll have parent relations to define a context!) is only yet another bargain with the Devil, who laughs at your precautions.”
And — using them (and comment fields) as a honey pot to find missing features:
“I'm surprised I haven't seen more discussion of how tags are an entry point into plain-old data architecture. It should be obvious that by the time you're using tags for queries like "start-date: BEFORE 2022-03-01", you've created an inner-platform where you're building a plain-old relational database on top of your tags. Stop what you're doing and elevate "start date" out of tag-land and into a more structured representation with more application support.
Many enterprise databases add a memo field called "Comments" to almost every table. Clients very often end up coming up with their own guidelines about how to embed various information in the comments fields that the primary structure is missing. Looking over how clients are using the "comments" fields is a great way to discover new things that should be formally incorporated into the structure of your data architecture. Similarly with tags.
Look at tags as a starting point for adding a bit of loose structure to the frontiers of your data architecture. Mix them in with more structured data architecture. Be ready to "graduate" tags up to the next level of structure when it becomes appropriate. Stop worrying about how to make tagging perfect and embrace it for what it is: an easy way to get started on modeling the parts of the domain that you haven't spent a long time thinking about yet. A good way to understand how users want to use your system. Something you're always revisiting, cleaning up, and using as a source of inspiration. If you see some tags getting out of hand, don't try to improve your tagging system; instead take what those tags are trying to represent and add more structured fields and queries for them. This pipeline of less to more structure should be constantly playing out in a healthy, evolving system.”
Performance of querying
It can be challenging to store tags in such a way that they can be efficiently queried.
For example, if an article has three tags: "Truth Beauty Wisdom" -- a naive implementation may store this in a single column, called "Tags" with the value "Truth Beauty Wisdom".
To find all items with the tag "Truth" you would use a SQL Where clause such as Where Tags like '%truth%'. This has two problems: correctness and performance. The correctness issue is that it would also return any item tagged with "Nontruth". A quite major flaw. The performance problem is that no index would be used during the search -- the query would need to scan the entire table. And if the "Tags" column is a nvarchar(max) type, each of these would need to be retrieved from outside the table's page.
To fix both problems, each tag would be stored in its own row.
The problem of “performance” is mentioned as a “solved” problem here:
I adore tagging systems and have worked on them in several different applications and implementations, but there are always pitfalls and trade offs, and it’s possible to bury yourself
Nowadays I nearly always store the assigned tags as an integer array column in Postgres, then use the intarray extension to handle the arbitrary boolean expression searches like “((1|2)&(3)&(!5))”. I still have a tags table that stores all the metadata / hierarchy / rules, but for performance I don’t use a join table. This has solved most of my problems. Supertags just expand to OR statements when I generate the expression. Performance has been excellent even with large tables thanks to pg indexing.
Tagging is political
Here is a fascinating "real world" example of tagging being used for an unexpected purpose.
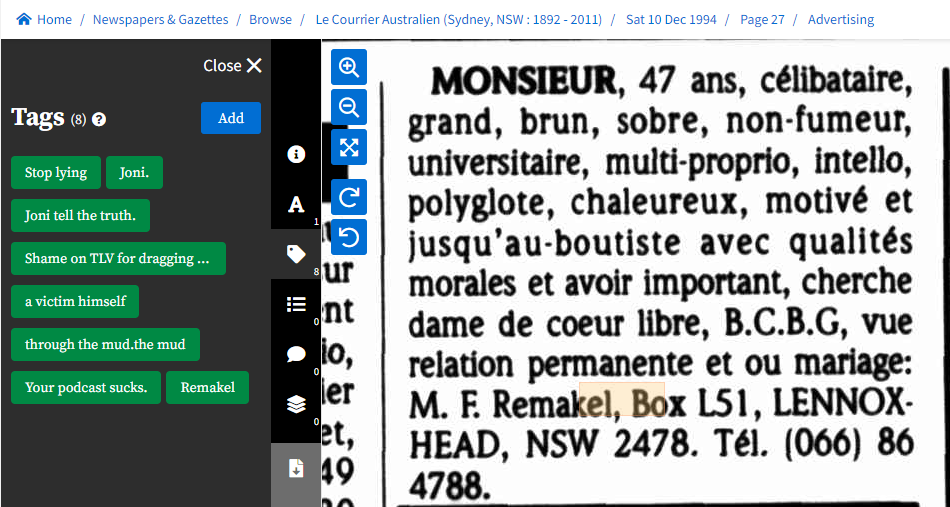
In 1997, Marion Barter went missing. It was later discovered that prior to going missing she had changed her name to "Florabella Natalia Marion Remakel".
The missing person's case was stalled for a long time, until the missing woman's daughter teamed up with journalists and created a podcast, which gained a following of loyal sleuths.
One of those sleuths, Joni, found the entry above in "Trove" (here). That entry revealed that someone using the name "Remakel" had placed a "lonely hearts" advertisement in a French language Australian newspaper, a few years before Marion went missing.
It was a critical turning point in the case. The clue was very hard to find, as an OCR error meant that the text was originally recorded incorrectly.
With police unwilling to pursue the case, the podcast creators travelled around the world to interview a man living in Luxembourg who matched the description from the lonely hearts advertisement. The journalists received a lot of criticism for this -- and the tags shown on the article above, are an example of that criticism. Journalists (not the Police) later found that the phone number on that advertisement was, during 1995, associated with a business called Ballina Coin, that was operated by a convicted fraudster, who soon became the main subject of inquiries in the case, which by this stage was treated as a homicide case. In those tags though, we see a protest against the sleuth who originally uncovered the clue.